
同学们好!对于RPC而言,JSON的确可以实现有效的跨语言的序列化和反序列化,但它毕竟不是专门为RPC设计的描述语言,可以很好地描述数据,却不能很好地描述服务。与文本形式的JSON不同,ProtoBuf是一种基于二进制的编解码标准,其在数据描述和服务描述两个方面,都具有同样卓越的表现,在基于RPC的程序开发中,应用得十分广泛。
在简单了解ProtoBuf的基本概念后,我们将尝试安装ProtoBuf并学习ProtoBuf的语法和编译,最后我们还要了解ProtoBuf的序列化反序列化及其与其它序列化反序列化机制的对比。

首先我来了解一下ProtoBuf的基本概念。

ProtoBuf的全称为Protocol Buffer,是谷歌公司开发的一种数据描述语言。它通过一种轻便高效的数据存储格式,为结构化数据提供序列化反序列化机制。ProtoBuf既可用于数据的存储,也可用于数据的交换。ProtoBuf与系统平台无关,与编程语言无关,而且非常易于扩展。截至目前,ProtoBuf已经提供了包括C/C++、Java、Python、Go等语言在内的应用编程接口。ProtoBuf对数据的描述和表现能力,完全可以与相对传统的XML和近年流行的JSON相媲美,同时对基于RPC的应用程序开发,提供了更好的支持。

相比于XML和JSON,经ProtoBuf序列化后的数据量更小,更适于在网络上传输。跨平台、支持多种编程语言、消息格式升级后的向下兼容性更好,以及序列化反序列化的速度更快等,都使得基于ProtoBuf的数据描述和应用开发要比使用其它工具更具优势。但不可否认,ProtoBuf也确实存在一些不足。比如它的应用,至少就目前来讲还不够广泛。它的序列化结果也不是XML或JSON那样的纯文本,而是一个二进制流,可读性比较差。另外ProtoBuf还缺乏象XML那样的自描述能力。

Go语言本身并不提供对ProtoBuf的开发支持,因此在Go语言程序中使用ProtoBuf需要单独安装。
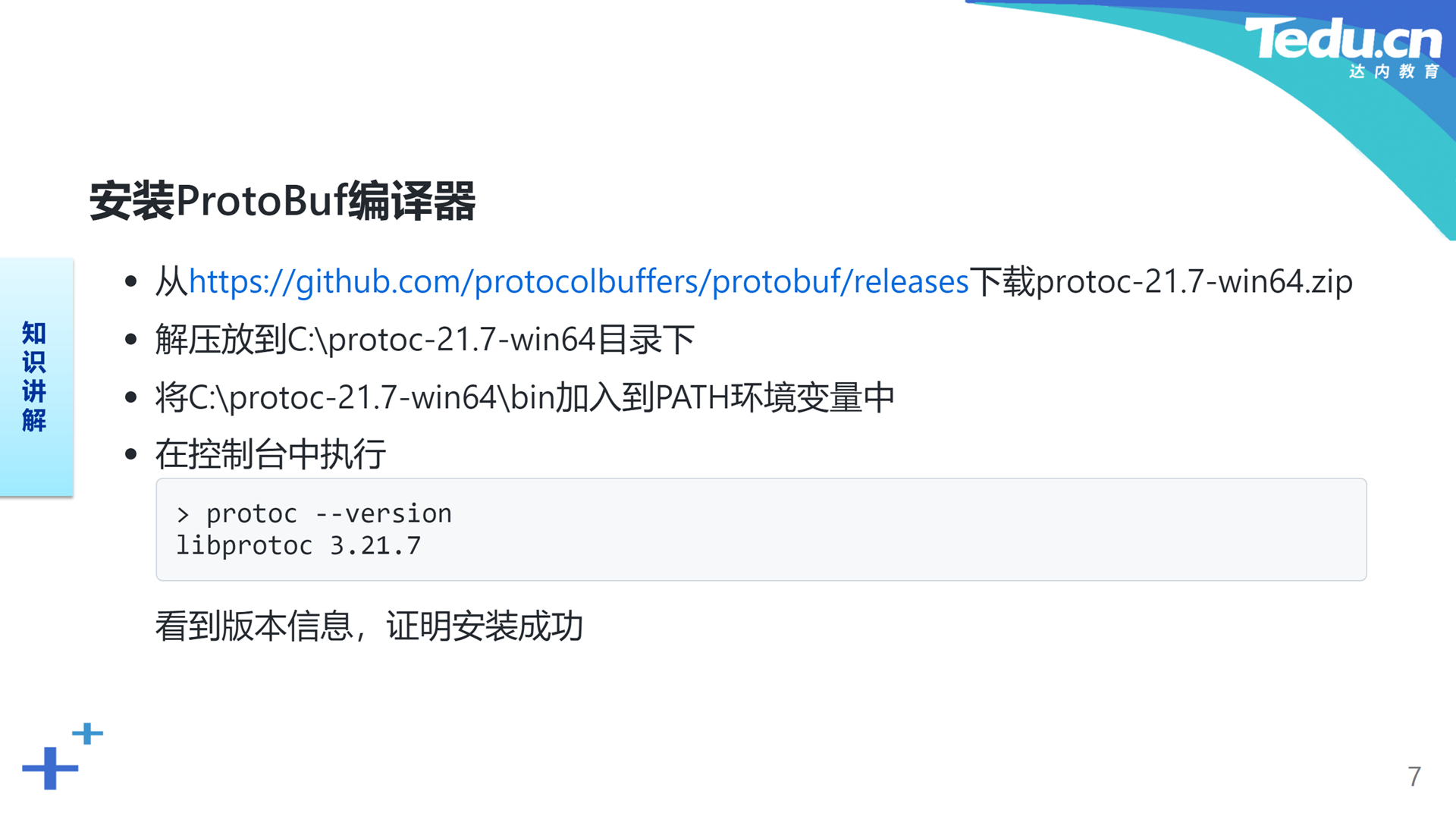
安装ProtoBuf首先需要安装它的编译器。ProtoBuf编译器的作用是将使用特定语法描述的数据结构转换为可被某种编程语言直接操作的数据类型。比如将扩展名为“.proto”的文件编译为扩展名为“.go”或者“.java”的文件。我们可以直接从GitHub上下载ProtoBuf编译器的发行包,通常就是一个压缩文件,解压到特定目录下,将其中的bin目录添加到PATH环境变量中。运行ProtoBuf编译器的命令是protoc。
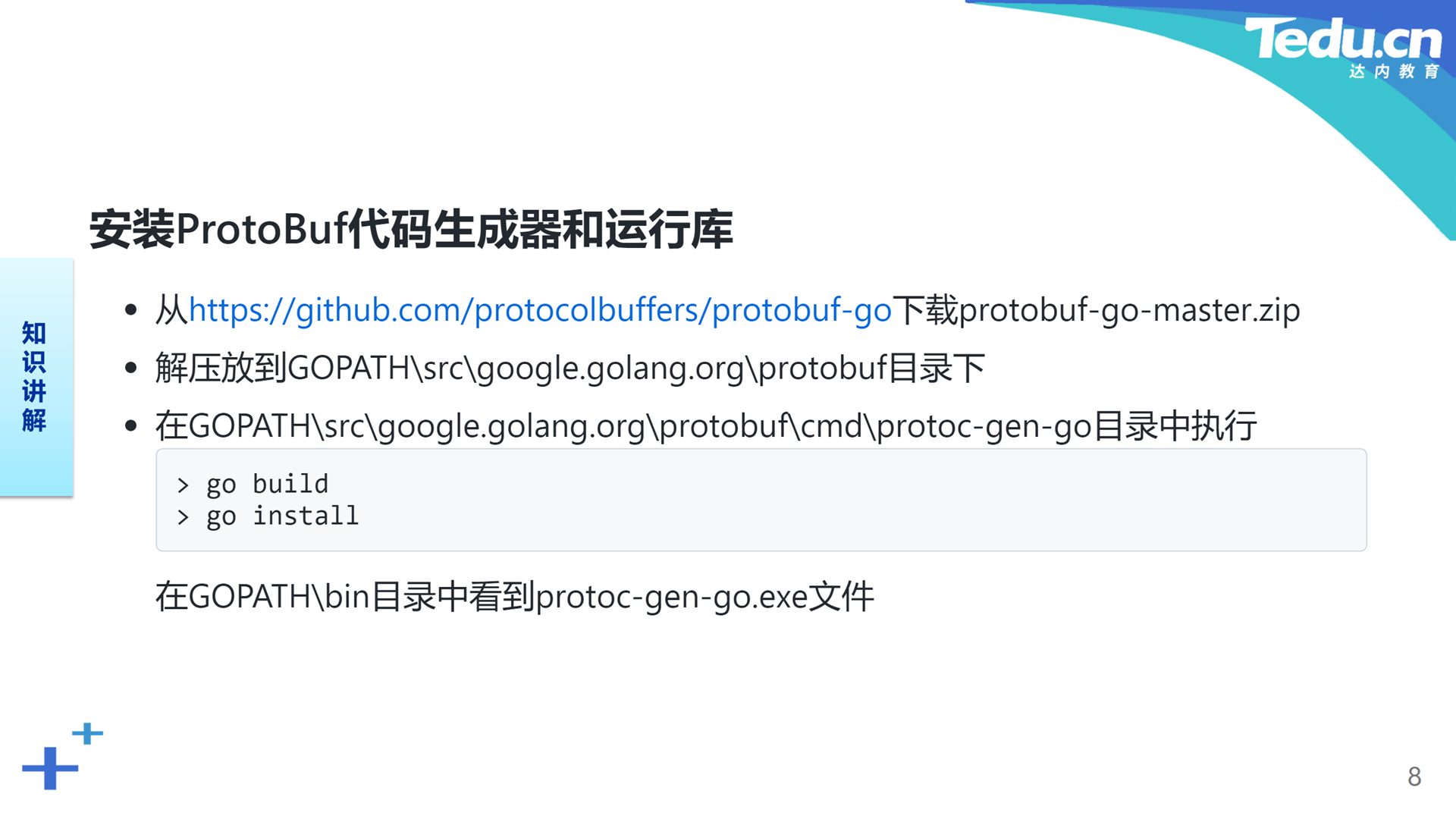
为了让ProtoBuf编译器能够顺利地将扩展名为“.proto”的文件编译为扩展名为“.go”的文件。我们需要安装ProtoBuf的Go语言代码生成器。同时为了让代码生成器生成的Go语言代码能够顺利地被Go语言编译器编译,并和我们编写的其它代码一起链接为可执行程序,我们还需要安装ProtoBuf运行库。我们可以直接从GitHub上下载protobuf-go项目,放到GOPATH的特定目录下,并在代码生成器目录下完成构建和安装。

ProtoBuf描述结构化数据有一套自己的语法。它和我们平常使用的编程语言的语法有关系但不完全一致,二者之间的转换由ProtoBuf编译器负责。

ProtoBuf描述结构化数据的核心元素是消息。ProtoBuf的消息可以类比Go语言的结构体,其中包含0到N个字段,每个字段均带有一个编号。消息字段的编号不一定非要从1开始,尽管通常都是从1开始的,关键是不能重复,也不能位于19000到19999区间内。消息字段的类型可以是整数、字符串、数组、枚举、联合,也可以是另一个消息。
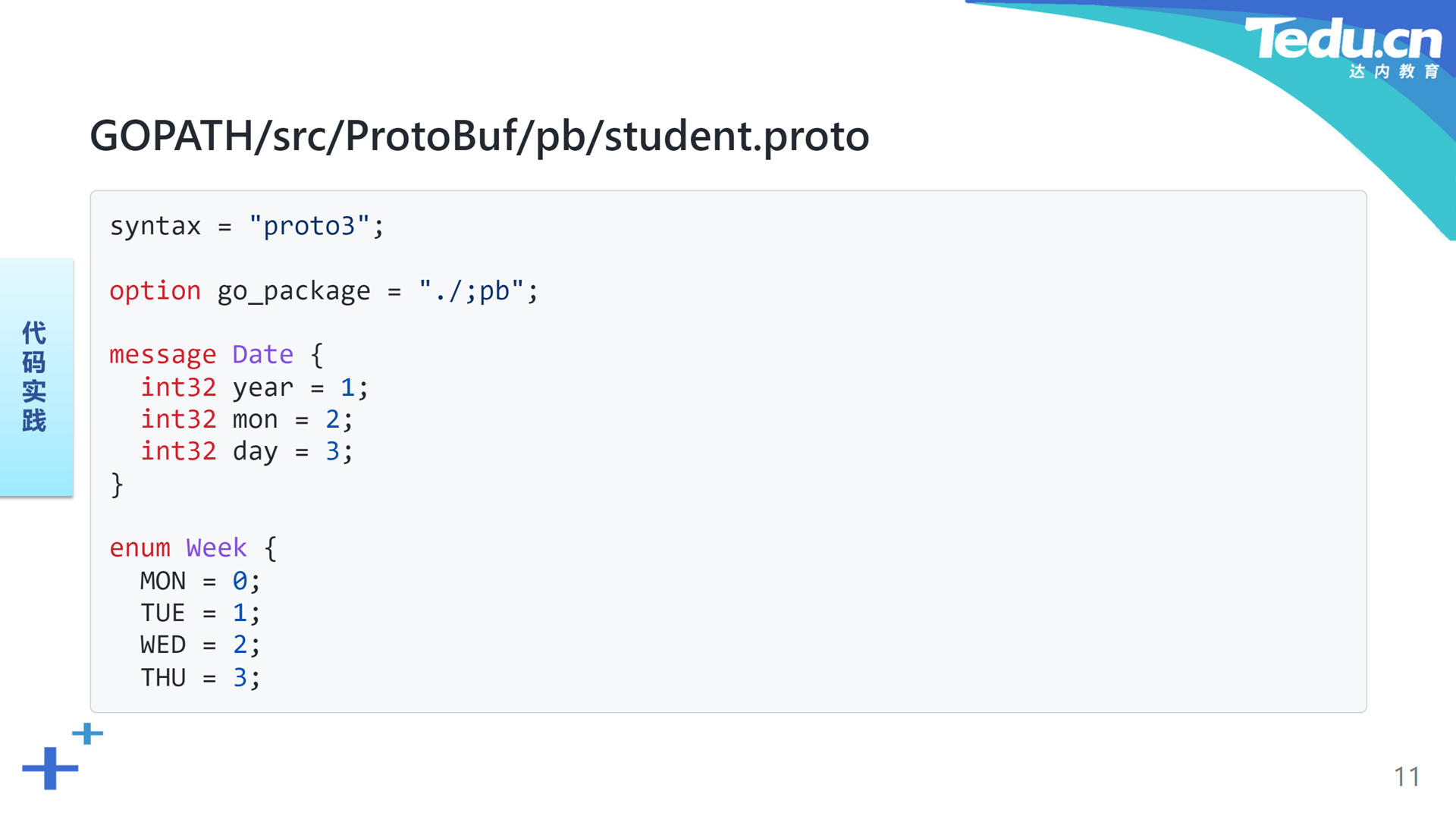
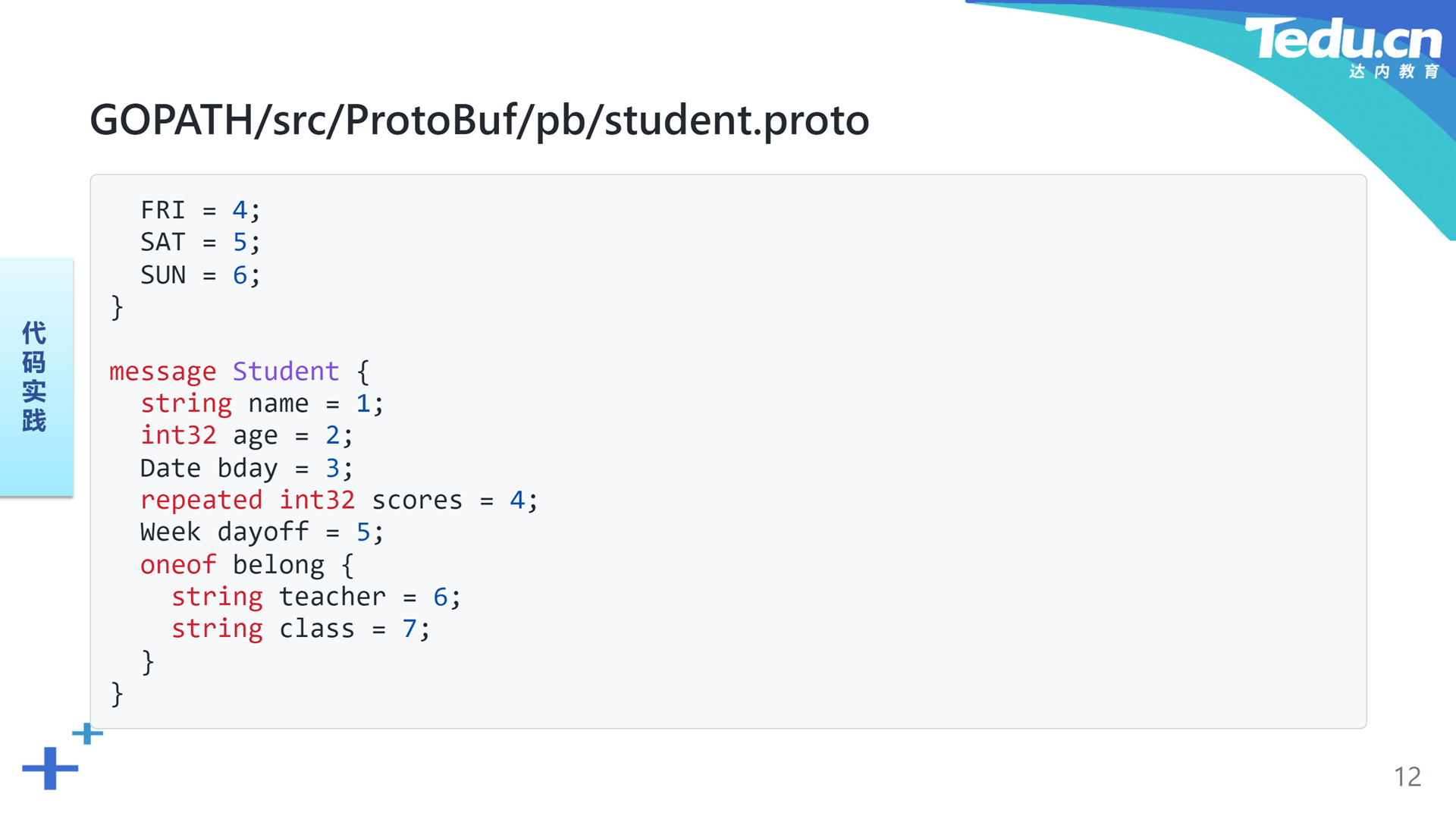
在名为ProtoBuf的工程目录下创建一个子目录pb,在该目录下编辑一个名为student.proto的脚本文件:
x1syntax = "proto3";2
3option go_package = "./;pb";4
5message Date {6 int32 year = 1;7 int32 mon = 2;8 int32 day = 3;9}10
11enum Week {12 MON = 0;13 TUE = 1;14 WED = 2;15 THU = 3;16 FRI = 4;17 SAT = 5;18 SUN = 6;19}20
21message Student {22 string name = 1;23 int32 age = 2;24 Date bday = 3;25 repeated int32 scores = 4;26 Week dayoff = 5;27 oneof belong {28 string teacher = 6;29 string class = 7;30 }31}在这段脚本的开始部分,首先指明其遵循的语法标准源自proto3。在被ProtoBuf编译器编译成Go语言代码后,其隶属的包为pb。Date是一个消息,表示日期,包含三个整数字段,分别表示日期中的年、月和日。Week是一个枚举,包含从MON到SUN七个字段,其值为从0到7的整数序列,表示一星期中的七天。这里的核心消息是Student,表示学生,包含六个不同类型的字段,字符串型的name表示姓名,整数型的age表示年龄,Date型的bday表示生日,整数数组型的scores表示成绩表,Week枚举型的dayoff表示休假日,最后一个是联合型的belong表示隶属关系。一个学生可以隶属于某位教师,也可以隶属于某个班级。这里使用了表示整数和字符串的int32和string关键字,以及分别表示消息、枚举、数组和联合的message、enum、repeated和oneof关键字。在表示消息的结构中,每个字段后面都有一个等号和数字。该数字表示相应字段的编号,并非其值。

上面的student.proto文件只是一个基于ProtoBuf语言的数据描述脚本,它既不能被Go语言编译器所理解,其中的数据结构也不能被Go语言代码所访问。为了让我们编写的Go语言程序能够使用在数据描述脚本中描述的数据结构,需要将其编译为Go代码,并和我们编写的其它代码一起参与可执行程序的构建。
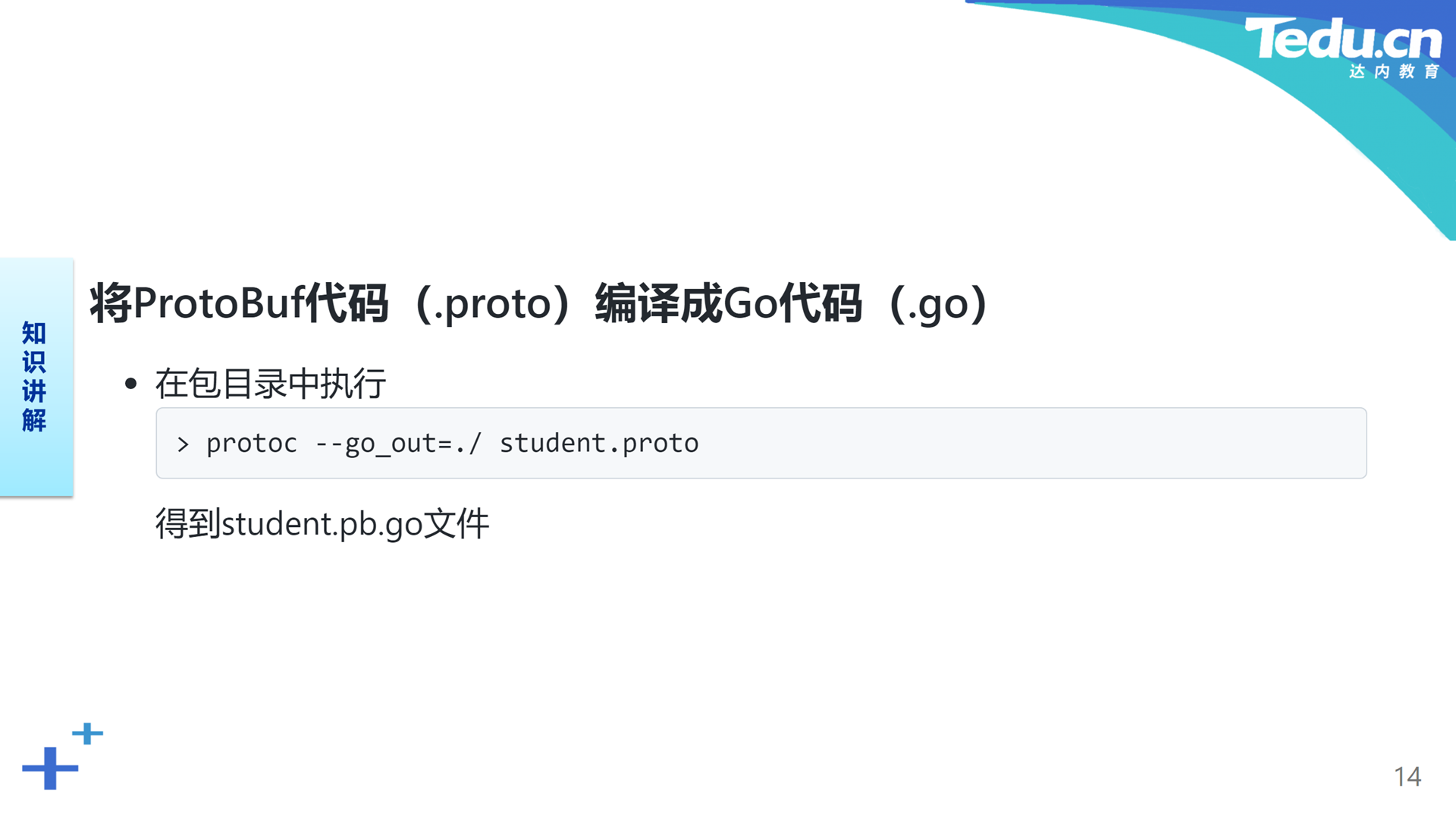
将扩展名为“.proto”的ProtoBuf脚本文件编译为扩展名为“.go”的Go语言代码文件,需要借助于ProtoBuf编译器。执行编译的方法就是在正确的路径下使用protoc命令,并在参数中指明Go语言代码文件的输出路径和ProtoBuf脚本文件。编译的结果是在所指定输出路径下的Go语言代码文件。
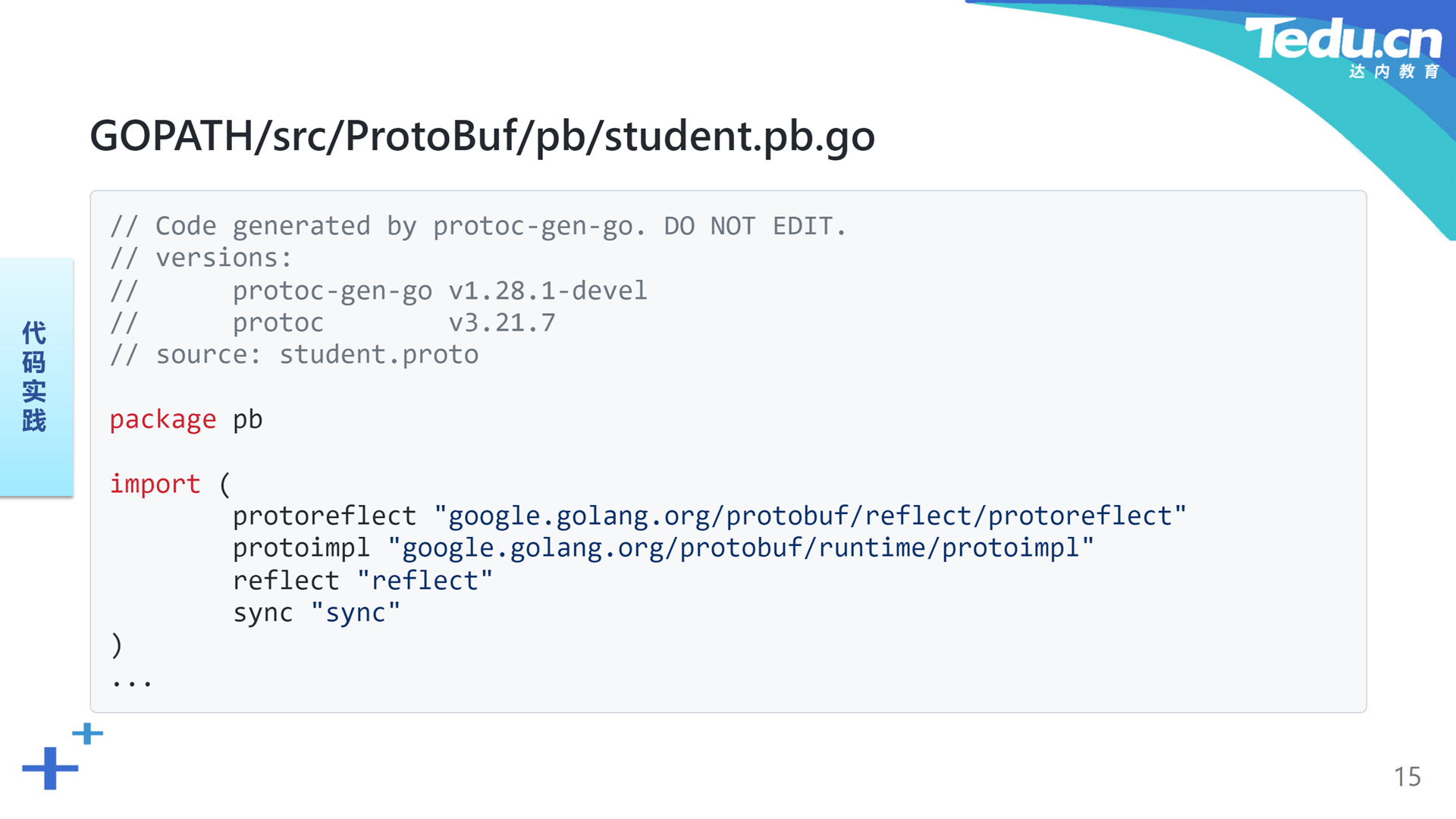
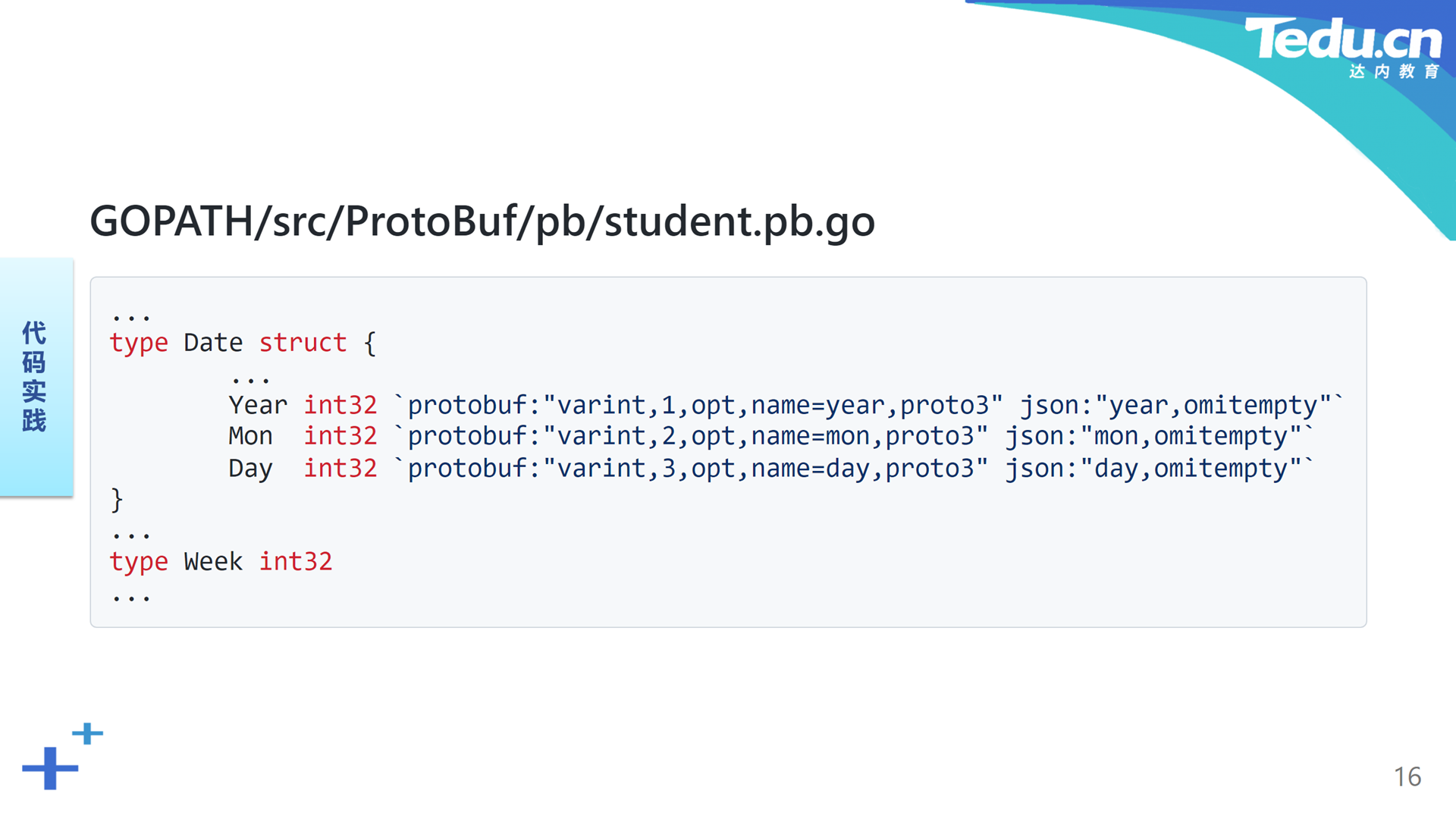
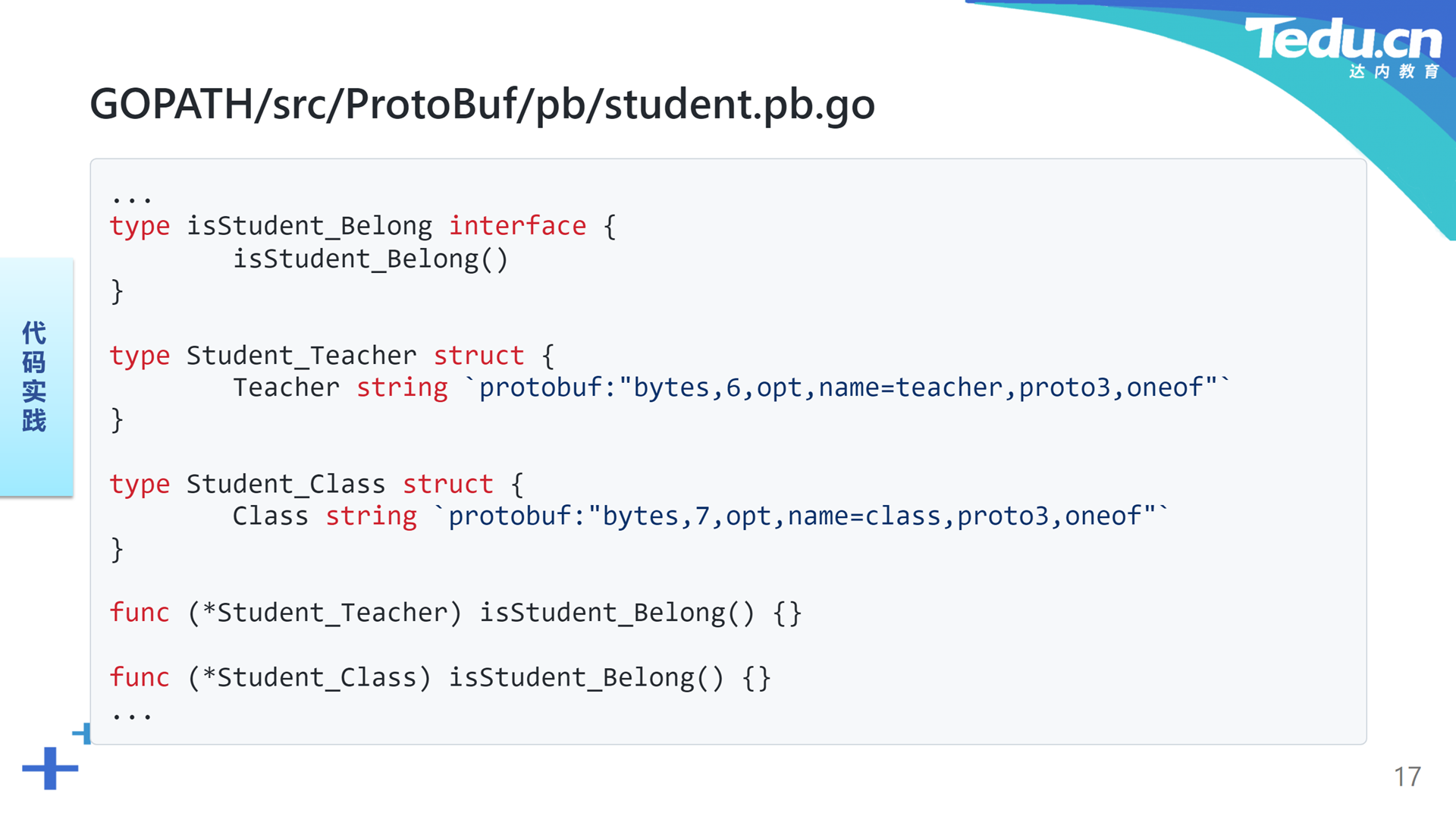
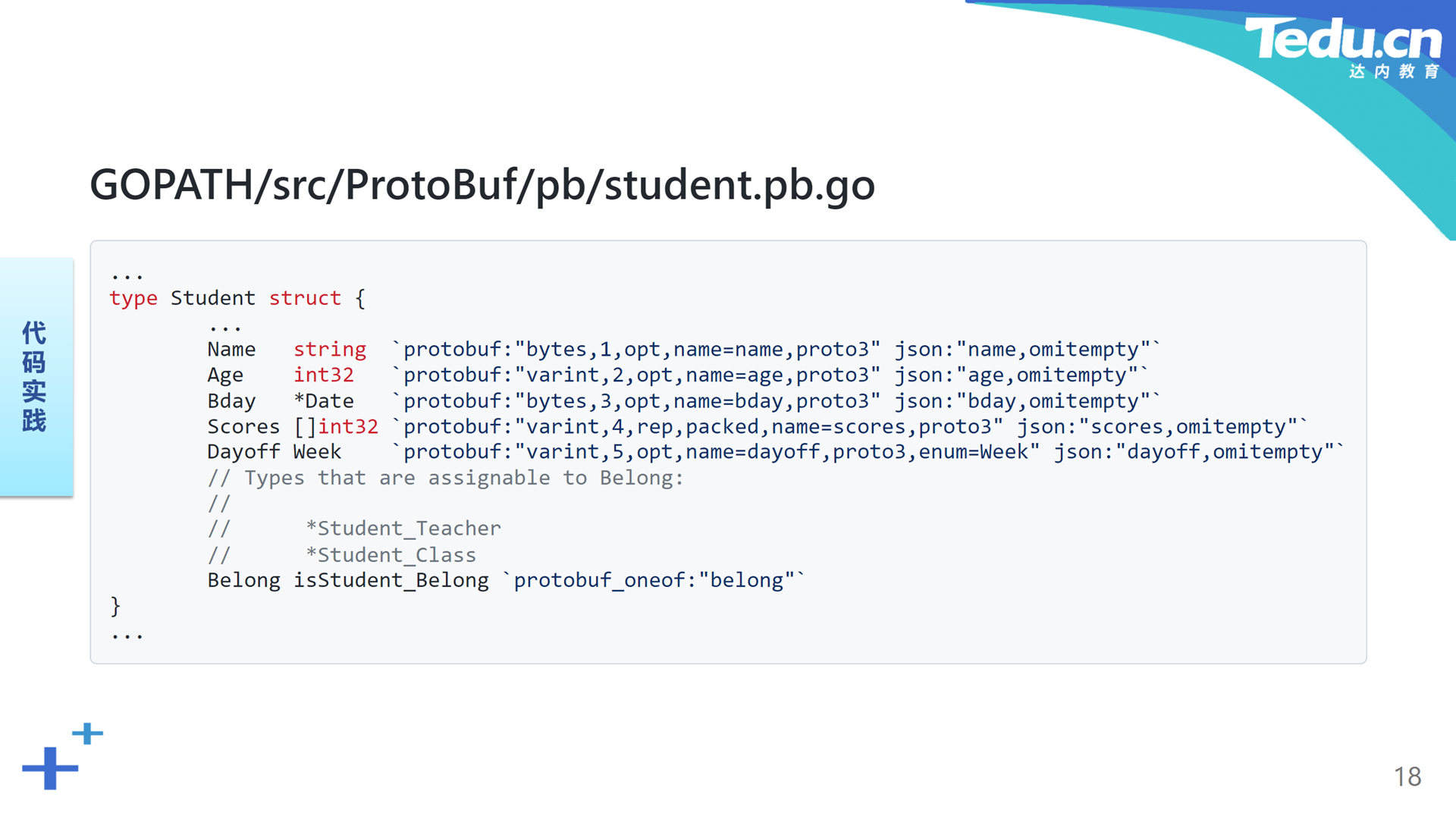
这里我们以student.proto为例,编译得到student.pb.go。简单浏览一下student.pb.go文件。首先我们看到这里导入了一些protobuf-go项目中的包。Date消息被编译为Date结构,分别表示年月日的三个成员依然历历在目。在每个成员的反引号标签中注明了该成员与ProtoBuf和JSON的联系。表示星期的枚举Week被编译为一个整型。Student消息被编译为Student结构,各个消息字段也都被编译为相应类型的结构体成员。表示隶属关系的联合belong被编译为一个接口,联合中的一个字段对应该接口的一个实现类。
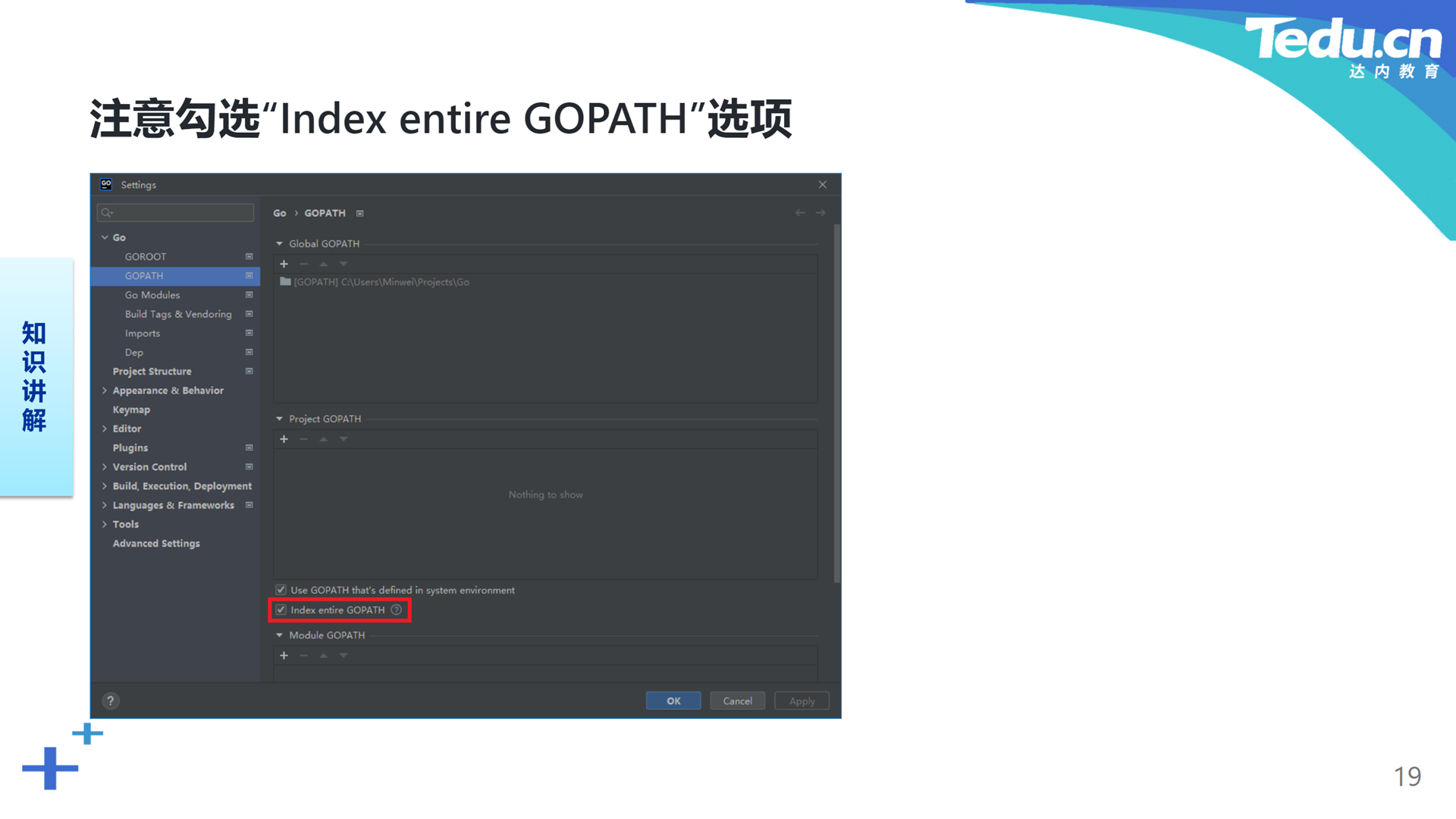
注意,为了避免GoLand集成开发环境在导入protobuf-go项目中的包时报红,请确认工程配置中的“Index entire GOPATH”选项被勾选。

下面我们将基于student.pb.go中的代码,构建一个可执行程序,验证ProtoBuf对数据序列化和反序列化的支持。


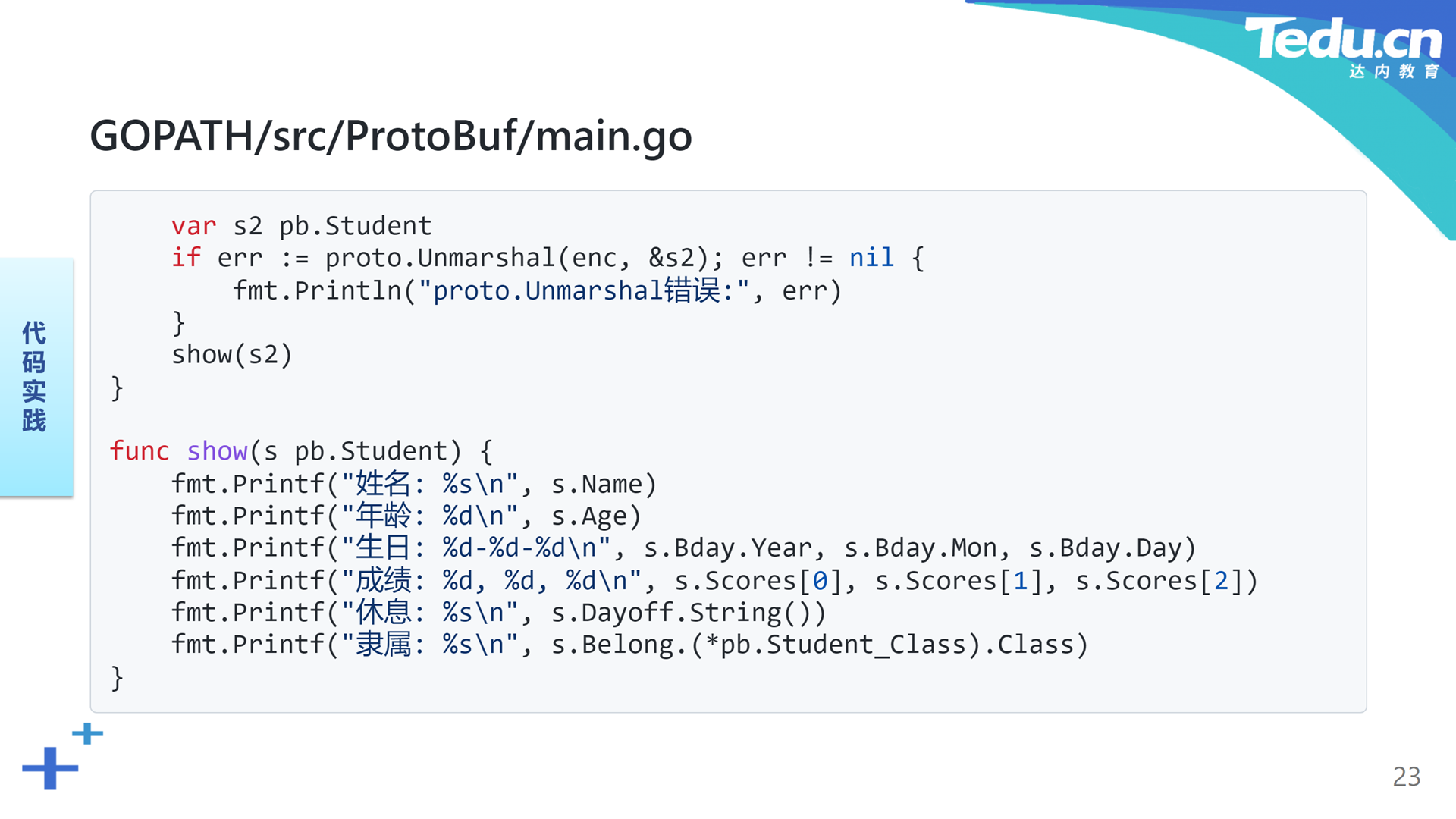

在ProtoBuf工程中增加main.go:
xxxxxxxxxx471package main2
3import (4 "ProtoBuf/pb"5 "fmt"6 "google.golang.org/protobuf/proto"7)8
9func main() {10 s1 := pb.Student{11 Name: "张飞",12 Age: 20,13 Bday: &pb.Date{14 Year: 2002,15 Mon: 11,16 Day: 11,17 },18 Scores: []int32{80, 90, 100},19 Dayoff: pb.Week_WED,20 Belong: &pb.Student_Class{21 Class: "高二3班",22 },23 }24 show(s1)25
26 enc, err := proto.Marshal(&s1)27 if err != nil {28 fmt.Println("proto.Marshal错误:", err)29 return30 }31 fmt.Println(enc)32
33 var s2 pb.Student34 if err := proto.Unmarshal(enc, &s2); err != nil {35 fmt.Println("proto.Unmarshal错误:", err)36 }37 show(s2)38}39
40func show(s pb.Student) {41 fmt.Printf("姓名: %s\n", s.Name)42 fmt.Printf("年龄: %d\n", s.Age)43 fmt.Printf("生日: %d-%d-%d\n", s.Bday.Year, s.Bday.Mon, s.Bday.Day)44 fmt.Printf("成绩: %d, %d, %d\n", s.Scores[0], s.Scores[1], s.Scores[2])45 fmt.Printf("休息: %s\n", s.Dayoff.String())46 fmt.Printf("隶属: %s\n", s.Belong.(*pb.Student_Class).Class)47}在这段代码中,我们首先用student.pb.go中的Student结构创建并初始化了一个代表学生的对象s1。而后通过proto包的Marshal方法将其序列化为一个字节切片形式的二进制流enc。最后再通过proto包的Unmarshal方法,将enc反序列化为另一个Student类型的对象s2。通过对s1和s2的比较,验证ProtoBuf序列化和反序列化的正确性。

在这节课的最后,我们从几个不同的维度,对包括ProtoBuf、JSON、XML、Lua等在内的几种常见序列化反序列化方法做一番对比。
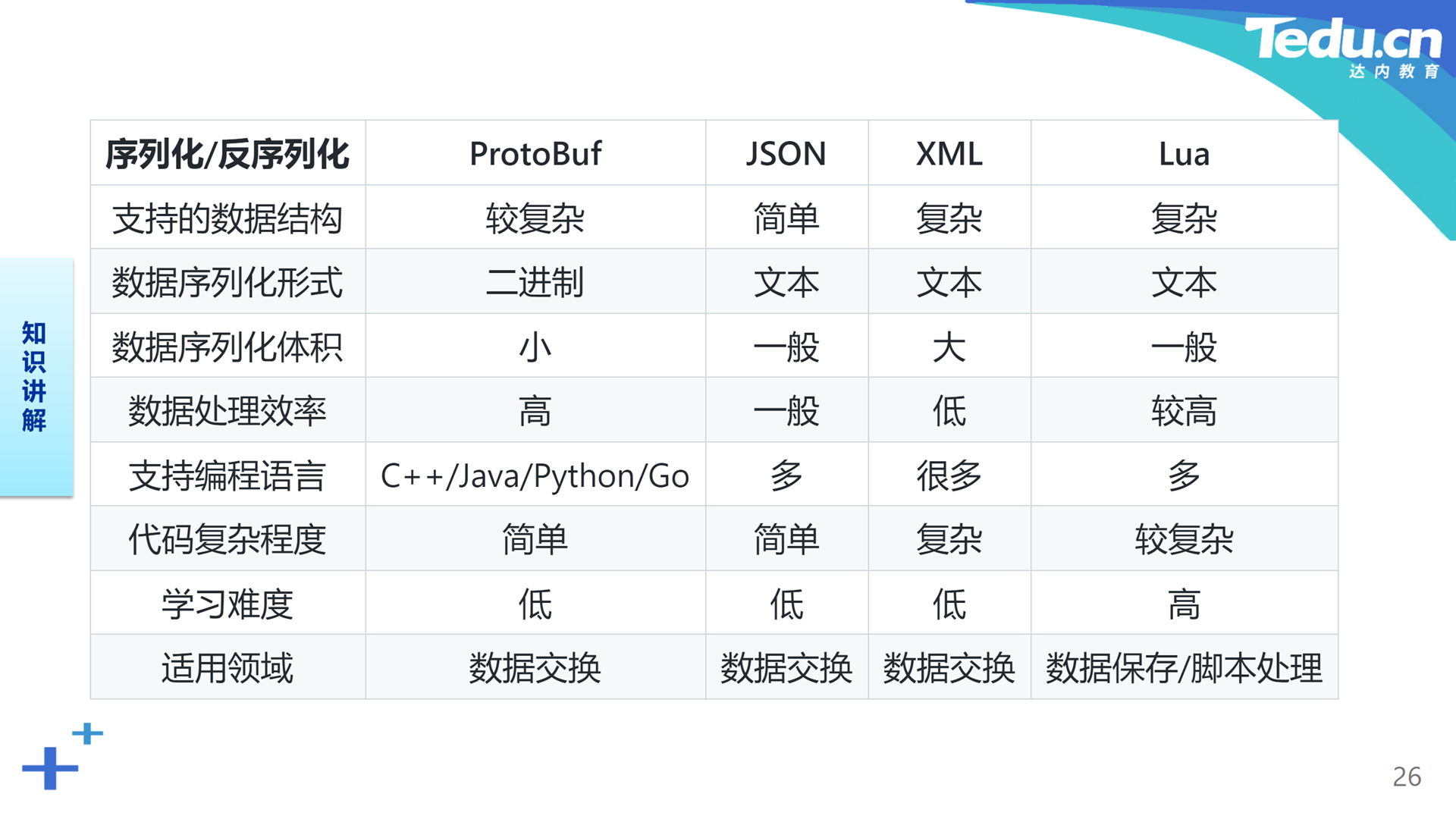
从这张表中不难看出,在所描述的数据复杂度方面,ProtoBuf的表现相对中庸,可以满足大多数应用系统对数据复杂度的要求。在数据序列化形式方面,只有ProtoBuf采用二进制流的形式。也正因为如此,基于ProtoBuf的数据序列化体积最小,效率最高。在所支持的编程语言方面,ProtoBuf显然不是最多的,目前仅支持C++、Java、Python和Go四种编程语言。基于ProtoBuf描述结构化数据的代码复杂度和学习难度都非常低。ProtoBuf和其它序列化反序列化方法一样,主要应用于数据交换的场合。

谢谢大家,我们下节课再见!